신뢰 구간
신뢰 구간이란 무엇입니까?
이는 모집단 매개 변수를 포함하는 통계에 사용되는 범위의 추정치입니다. 이 알려지지 않은 모집단 매개 변수는 수집 된 데이터로부터 계산 된 샘플 모델을 통해 발견됩니다.
예 : 수집 된 샘플의 평균은 x x와 같을 수도 있고 그렇지 않을 수도 있습니다. 이를 위해, 이 모집단 평균이 포함될 수있는 샘플 범위의 범위를 고려하는 것이 가능합니다. 이 간격이 길수록이 발생 가능성이 커집니다.
신뢰 구간은 신뢰 수준에 의해 표시되는 백분율로 표시되며 90 %, 95 % 및 99 %가 가장 많이 표시됩니다. 예를 들어 아래 그림에서 상한과 하한 사이의 신뢰 구간은 90 %입니다 (a 및 -a ).
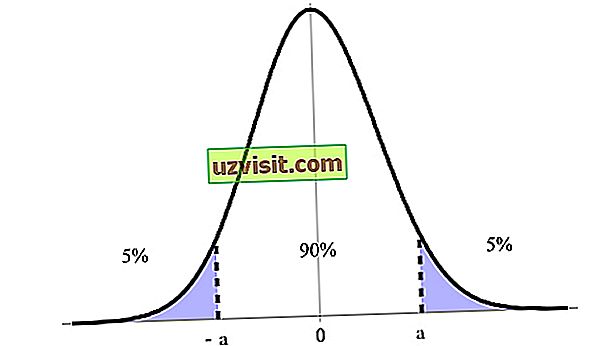
신뢰 구간은 불확실성의 척도로 사용되기 때문에 통계에서의 가설 테스트에서 가장 중요한 개념 중 하나입니다. 이 용어는 1937 년 폴란드의 수학자이자 통계 학자 Jerzy Neyman 에 의해 소개되었습니다.
신뢰 구간의 관련성은 무엇입니까?
신뢰 구간은 계산에 대한 불확실성 (또는 부정확성)의 마진을 나타내는 데 중요합니다. 이 계산은 스터디 샘플을 사용하여 소스 모집단에서 결과의 실제 크기를 추정합니다.
신뢰 구간의 계산은 오류 샘플링을 고려한 전략입니다. 연구 결과의 크기와 신뢰 구간은 원래 모집단의 추정치를 특성화합니다.
신뢰 구간이 좁을수록 연구 집단의 비율이 원 자료 집단의 실제 수를 나타내는 확률이 높아 학습 개체의 결과에 대한 확실성이 높아집니다.
신뢰 구간을 해석하는 방법?
아마도 신뢰 구간의 정확한 해석은이 통계적 개념에서 가장 도전적인 측면 일 것입니다. 개념의 가장 일반적인 해석의 예는 다음과 같습니다.
미래에는 모집단 매개 변수의 실제 값 (예 : 평균)이 X (하한) 및 Y (상한) 범위에 속할 확률 이 95 % 입니다.
따라서 신뢰 구간은 다음과 같이 해석됩니다. X (하한)와 Y (상한) 사이의 간격이 모집단 매개 변수의 실제 값을 포함한다는 것이 95 % 신뢰됩니다.
X (하한)와 Y (상한) 사이의 간격이 모집단 매개 변수의 실제 값을 포함하는 확률은 95 %입니다.
위의 진술은 신뢰 구간에 대한 가장 일반적인 오해입니다. 통계적 범위를 계산 한 후에는 모집단 매개 변수 만 포함 할 수 있습니다.
그러나 샘플마다 간격이 다를 수 있지만 실제 모집단 매개 변수는 샘플에 관계없이 동일합니다.
따라서, 신뢰 구간 신뢰 진술은 신뢰 구간이 샘플 개수에 대해 재 계산되는 경우에만 이루어질 수있다.
신뢰 구간 계산 단계
범위는 다음 단계를 사용하여 계산됩니다.
- 샘플 데이터 수집 : n ;
- 표본 평균을 구한다. x̅;
- 모 표준 편차 ( σ )가 알려 졌는지 알 수 없는지를 결정하십시오.
- 모 표준 편차가 알려져 있다면, 해당 신뢰 수준에 z- 점을 사용할 수 있습니다.
- 모집단 표준 편차가 알려지지 않은 경우 해당 신뢰 수준에 대해 통계량 t 를 사용할 수 있습니다.
- 따라서 신뢰 구간의 상한 및 하한은 다음 공식을 사용하여 구할 수 있습니다.
a) 알려진 모집단의 표준 편차 :
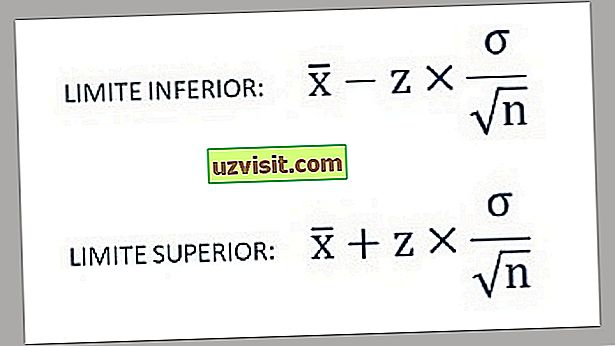
알려진 모집단의 표준 편차를 계산하기위한 공식.
b) 미지의 개체군의 표준 편차 :

알 수없는 모집단의 표준 편차를 계산하는 수식입니다.
신뢰 구간의 실제 예
임상 연구는 천식의 존재와 성인의 폐쇄성 수면 무호흡증을 유발할 위험 사이의 연관성을 평가했습니다.
일부 성인은 4 년 동안 계속 지켜지기 위해 국가 공무원 명부에서 무작위로 모집되었다.
천식 환자는 천식이없는 환자와 비교했을 때 4 년간 무호흡이 발병 할 위험이 더 큽니다.
이 예와 같은 임상 연구를 수행 할 때 관심 대상 집단의 하위 집합은 일반적으로 연구 효율을 높이기 위해 모집됩니다 (비용 절감 및 시간 단축).
연구 대상 집단 인이 개인 하위 집단은 아래 이미지와 같이 포함 기준을 충족하고 연구 참여에 동의하는 사람들로 구성됩니다.

그런 다음 연구가 완료되고 연구 질문에 대답하기 위해 효과 크기 (예 : 평균 차이 또는 상대 위험 )가 계산됩니다.
추론 이라고하는이 과정에는 관심 인구, 즉 출신 인구에 대한 실제 효과의 크기를 추정하기 위해 연구 집단에서 수집 한 데이터를 사용합니다.
주어진 예에서, 연구자들은 연구에 참여할 자격이 있고 (연구 집단) 천식이 연구 집단에서 무호흡 발병의 위험을 증가 시킨다는보고를 한 국가 직원 (출처 인구)의 무작위 표본을 모집했다.
관심있는 집단의 소그룹 모집으로 인한 표본 추출 오류를 설명하기 위해 95 % 신뢰 구간 (추정치 주위) 1.06 - 1.82를 계산하여 95 의 확률을 나타냈다 근원 개체수의 진정한 상대 위험은 1.06에서 1.82 사이 일 것 입니다.
평균에 대한 신뢰 구간
한 모집단의 표준 편차에 대한 정보가있을 때, 그 모집단의 평균 또는 평균에 대한 신뢰 구간을 계산할 수 있습니다.
측정되는 통계 특성 (예 : 소득, IQ, 가격, 높이, 양 또는 무게)이 숫자 인 경우 대부분의 경우 모집단의 평균값이 발견됩니다.
따라서 우리는 표본 평균 ( x̅ )을 사용하여 모집단 평균 ( μ )을 찾아서 오차 범위를 찾습니다 . 이 계산의 결과를 모집단 평균에 대한 신뢰 구간 이라고합니다.
모집단 표준 편차가 알려진 경우 모집단 평균에 대한 CI (신뢰 구간)의 공식은 다음과 같습니다.

장소 :
- x the 는 표본 평균이다.
- σ 는 모집단 표준 편차이다.
- n 은 샘플 크기입니다.
- Ζ * 는 원하는 신뢰도에 대한 표준 정규 분포의 적절한 값을 나타냅니다.
다음은 다양한 신뢰 수준 ( Ζ * )에 대한 값입니다.
| 신뢰 수준 | Z * 값 - |
|---|---|
| 80 % | 1.28 |
| 90 % | 1.645 (일반) |
| 95 % | 1.96 |
| 98 % | 2.33 |
| 99 % | 2.58 |
위 표는 제공된 신뢰 수준에 대한 z * 값을 보여줍니다. 이 값은 표준 정규 분포 (Z-)에서 구합니다.
각 z * 값과이 값의 음수 사이의 영역은 (대략적인) 신뢰도입니다. 예를 들어, z * = 1.28 및 z = -1.28 사이의 영역은 약 0.80입니다. 따라서이 표는 다른 신뢰도 비율로도 확장 될 수 있습니다. 이 표에는 가장 일반적으로 사용되는 신뢰도 만 표시됩니다.
가설의 의미도 참조하십시오.


